Is Your Website Visible to AI Agents?
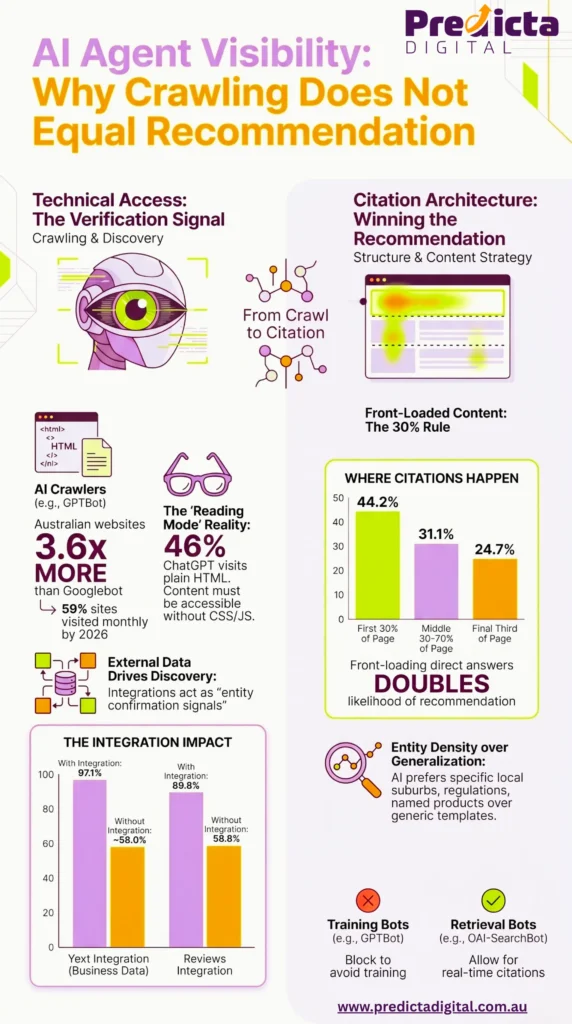
AI agents are crawling Australian websites right now. Not occasionally, but constantly. According to Search Engine Journal’s analysis of 68 million AI crawler visits across 858,457 sites, AI bots now crawl websites 3.6 times more frequently than Googlebot. By February 2026, 59% of those sites had received at least one AI crawler visit in a single month. Your site is almost certainly in that 59%.
The more important question is what happens after the crawl. AI agents are asking two things about your website. Can I actually read this? And is the content worth recommending? They are different questions with different answers, and most AI search optimisation advice does not clearly separate them. Here is what the data shows about both.
Can AI Agents Actually Read Your Site?
The first question is technical. AI crawlers do not browse like humans. They request your HTML, read it, and extract meaning from it without rendering CSS, executing JavaScript, or clicking through navigation. According to Search Engine Land’s testing of ChatGPT agent behaviour, 46% of visits began in reading mode: a plain HTML version of the page with no images, no CSS, no JavaScript, and no schema markup. If your content relies on any of those to be complete, agents may be visiting pages that look fine in Google Search Console and finding them partially empty.
Three things account for most readability failures:
- robots.txt blocking AI crawlers — often accidentally, via a security plugin or CDN default that was never meant to apply to legitimate search bots
- JavaScript-rendered content — if your service pages, FAQs, or location content load dynamically after a user interaction, agents read the shell, not the content
Structural noise — navigation bars, cookie banners, script tags and div wrappers consume AI processing capacity without contributing meaning. According to Cloudflare’s published data, a typical web page takes 16,180 tokens to process as raw HTML and 3,150 tokens as clean Markdown: an 80% reduction for the same content.

The robots.txt issue is worth checking first because it is the most common and fastest to fix. In 2024 and 2025, a number of SEO plugins — including configurations in Yoast, RankMath, and Cloudflare security settings — added ‘block AI bots’ toggles that defaulted to on. Many businesses running these configurations are blocking GPTBot, ClaudeBot and OAI-SearchBot without knowing it. We covered the specific version of this affecting Shopify stores and their AI visibility in detail. The same pattern repeats across WordPress sites on managed hosting.
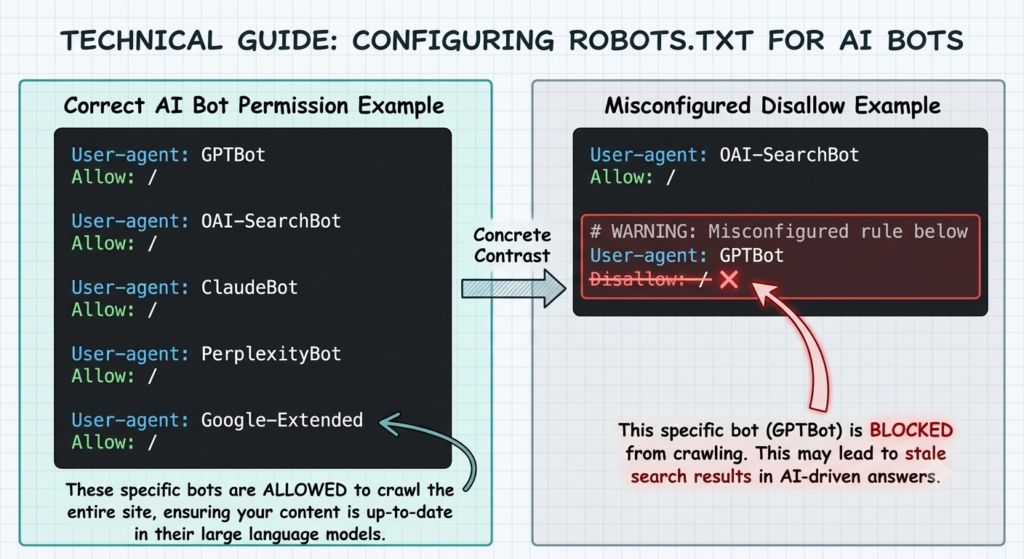
The pattern I keep seeing: the block isn’t in robots.txt. It’s one layer up, in Cloudflare, where a plugin update quietly switched on AI crawler blocking without a notification. The store or site looks open. The crawlers can’t get in.
The crawlers worth explicitly allowing are:
- GPTBot — OpenAI’s primary crawler
- OAI-SearchBot — OpenAI’s real-time retrieval crawler, the one that matters for live citations
- ClaudeBot — Anthropic’s crawler
- PerplexityBot — Perplexity’s indexing crawler
- Google-Extended — Google’s AI training and Gemini crawler
The distinction between training crawlers and retrieval crawlers matters here. Blocking GPTBot (training) while allowing OAI-SearchBot (retrieval) means ChatGPT can still cite you in real-time answers. Most robots.txt guides treat them as one category. They are not.
Our technical SEO checklist covers the full robots.txt configuration in detail.
The Crawl Data That Changes the Conversation
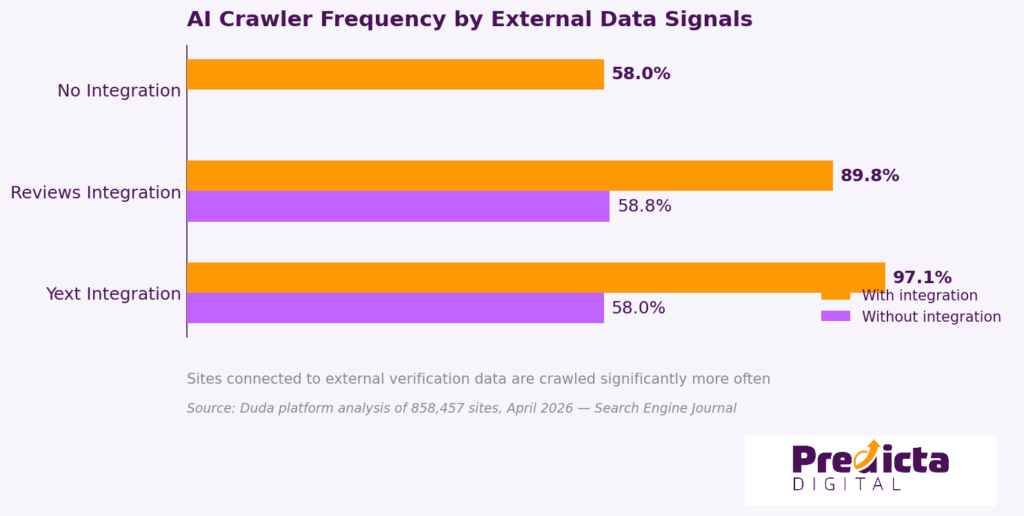
The SEJ analysis of 858,457 sites contains a finding that most AI SEO discussions skip: what predicts crawl frequency is not the infrastructure signals most agencies focus on. Sites connected to external business data systems are crawled dramatically more often than sites without them.
| Signal | Crawl rate with | Crawl rate without |
| Yext integration (external business data) | 97.1% | ~58% |
| Reviews integration | 89.8% | 58.8% |
| No integrations (site alone) | ~58% | — |
Source: Duda platform analysis of 858,457 sites, April 2026. Reported by Search Engine Journal.
The pattern here is about verifiability. AI systems crawl sites more frequently when those sites are connected to external data confirming the business is real and consistent: NAP data, reviews, structured business listings. It is an entity confirmation signal, not a technical infrastructure one.
But even high crawl rates do not translate directly to citations. A BuzzStream study of 4 million AI citations across 3,600 prompts found that roughly 70% of ChatGPT citations came from sites that were blocking ChatGPT’s retrieval bots. Citation decisions are largely driven by training data and authority accumulated over time. Being readable is a prerequisite. It is not a guarantee.
Is Your Content Worth Recommending?
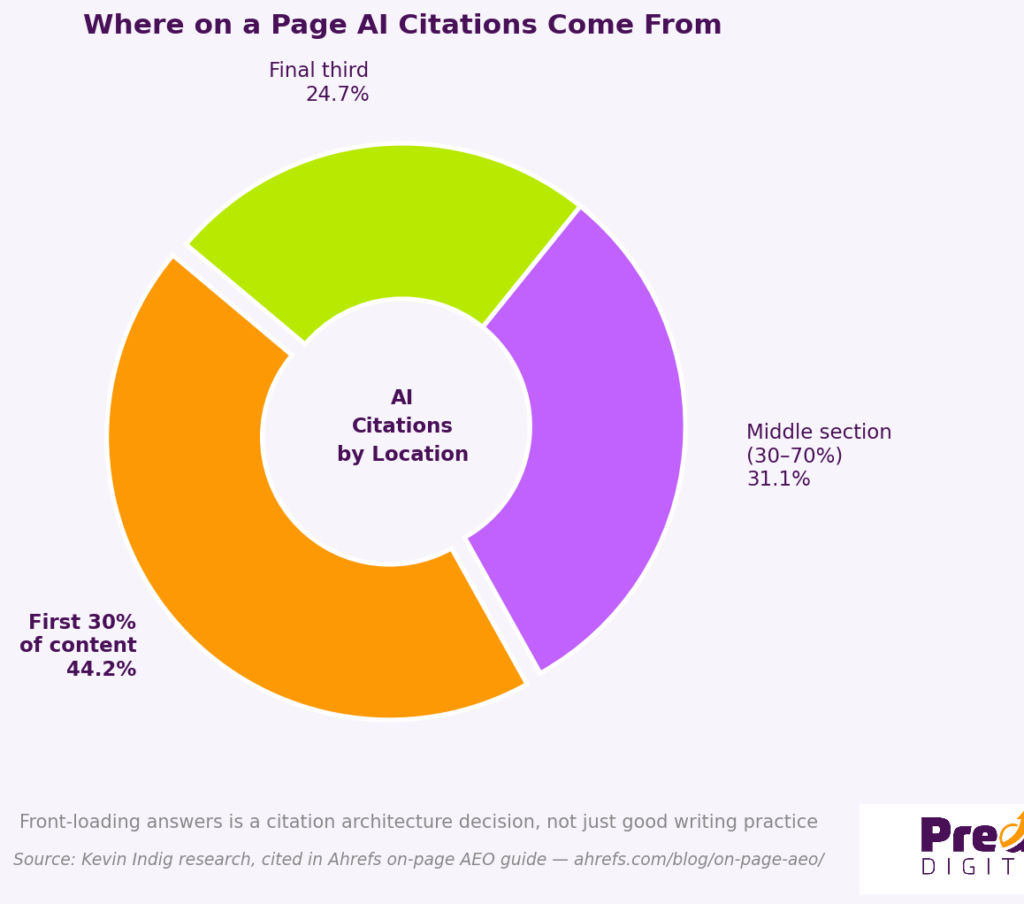
Content quality is where the evidence is strongest, and the gap between most Australian business websites and what AI systems actually prefer is most visible here. The AI SEO statistics for 2026 post covers the full data. The short version: according to Kevin Indig’s research cited in Ahrefs’ on-page AEO guide, 44.2% of AI citations come from the first 30% of page content. Pages that answer the question in the first paragraph are cited at roughly twice the rate of pages that build context first.
This is not a style preference. It is a citation architecture decision. AI systems lift the cleanest, most direct answer they can find. Content structured around a caveat-first, context-heavy professional tone is architecturally invisible to that retrieval pattern regardless of how good the underlying information is.
For local Australian service businesses, the additional advantage is specificity. A Melbourne tradie whose service pages name specific suburbs with real local context, or an NDIS provider writing about Queensland support coordination pathways, is producing content with entity density that a nationally scaled competitor cannot replicate at volume. AI systems have a shorter list of authoritative, locally specific sources to choose from. Yours can be one of them. Entity density is the concentration of specific, named things — businesses, locations, services, regulations, products — relative to total word count. National content templates produce low entity density because they are written to be applicable everywhere. That is not an accident. It is a structural disadvantage.
What Machine-Readable Infrastructure Does and Does Not Do
llms.txt, Markdown negotiation and other machine-readable protocols get significant attention in AI SEO discussions. Google’s own AI optimisation guidance states explicitly that you do not need new machine-readable files to appear in generative AI search.
Ahrefs ran a controlled study to test whether adding schema actually moves AI citation rates. They tracked 1,885 pages adding JSON-LD schema and found no meaningful citation uplift across AI Overviews, AI Mode, or ChatGPT over 30 days: AI Overviews moved -4.6%, AI Mode +2.2%, ChatGPT +2.4%, all within noise.
At the same time, Chrome’s Lighthouse shipped a dedicated llms.txt audit in its new Agentic Browsing category, last updated May 2026, and Cloudflare’s Markdown for Agents is being actively consumed by coding agents including Claude Code. Same infrastructure, two different use cases: general-purpose chatbot citations (evidence is weak) versus coding agent documentation lookups (evidence is real and observable).
Predicta’s own llms.txt is now live: a machine-readable index of our service pages and content, structured for agents that consult it before crawling further.
The schema.org precedent is worth knowing here. Schema was niche in 2011, table stakes by 2017, entity infrastructure by 2025. Agent-readiness protocols in 2026 are at a similar early stage. The cost of implementing is low. The option value if the standards develop is real. It is not the missing lever for citations next month.
| What the evidence supports | What it does not yet support |
|---|---|
| robots.txt AI permissions: Can help prevent accidental blocking of AI crawlers and content-fetching systems when correctly configured. | Does not appear to directly influence whether a page is cited by major chatbot answer engines. |
| Markdown negotiation: Delivering content in Markdown can reduce parsing complexity and token usage (often substantially in agent workflows) and improve content extraction reliability. | Does not appear to directly determine citation selection or ranking in chatbot responses. |
| llms.txt: May be useful for coding agents, developer tools, and systems that intentionally look for a standardized AI-readable site guide, especially when operating on known or hardcoded URLs. | There is no strong public evidence that major general-purpose chatbots currently use llms.txt as a significant citation or ranking signal. |
| Schema.org JSON-LD: Helps machines understand entities, authors, products, organizations, FAQs, articles, and relationships on a page; can improve structured content interpretation. | Does not have confirmed evidence as a direct ranking factor for AI citations or answer-engine inclusion on its own. |
Where to Start Depending on Your Business
Not every business needs the same intervention. The honest priority split:
| Business type | Priority | What to do first |
| SEO agency, SaaS, technical documentation site, AI-first product | Act now | Full infrastructure stack: robots.txt AI config, llms.txt with curated pages, Markdown negotiation. Content structure second. |
| Melbourne service business: trades, NDIS, professional services, Shopify store with 10k+ monthly visitors | Plan for it | Fix robots.txt AI permissions first. Ship a basic llms.txt. Confirm service pages are server-rendered HTML. Then prioritise content structure: direct answers, local specificity, entity density. |
| Small local business, under 5,000 visitors per month, infrequent content updates | One check | Verify robots.txt is not blocking AI crawlers. Beyond that, content quality and Google Business Profile consistency are the more valuable priorities right now. |
For SEO services in Melbourne across every business type, the starting point is the same: understand which of the two questions your site is currently failing on. Everything else follows from that.
The GEO, AEO and LLMO guide is a useful primer on how AI search discovery works before going into implementation.
Frequently Asked Questions
An AI agent is a software system that fetches live web content on behalf of an AI platform. When you ask ChatGPT, Perplexity or Google’s AI Mode a question involving current information, an agent retrieves pages and uses what it finds to construct an answer. Unlike traditional search crawlers, agents read for comprehension and citation rather than indexing for ranking. They cannot execute JavaScript, do not click through navigation, and read your HTML exactly as your server returns it.
Go to yoursite.com/robots.txt. Look for any Disallow rules applying to GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot or Google-Extended. If you are running Cloudflare, Yoast or RankMath, also check their security settings. These tools added ‘block AI bots’ defaults in 2024 that have left many sites unintentionally blocking legitimate retrieval crawlers. Check the Cloudflare dashboard under Security > Bots separately, as CDN-level blocks override your robots.txt entirely.
It depends on which agent. For coding agents like Claude Code that have documentation URLs hardcoded in their system prompts, an llms.txt file is directly useful as a curated index. For general-purpose AI assistants like ChatGPT grounding open-web answers, Google’s AI optimisation guidance confirms that new machine-readable files are not required to appear in generative AI search. A clean llms.txt is low cost with real future option value. Treat it as that rather than as a citation fix.
Content structure is the primary lever. Pages that answer the question directly in the opening paragraph, use specific entity-dense language (named locations, services, regulations), and contain genuinely Australian detail are cited more frequently. For service businesses, local specificity creates an entity density advantage that nationally templated content cannot match at scale. The GEO technical foundations guide covers both the content and infrastructure requirements in full.
Possibly yes. According to Search Engine Land’s ChatGPT agent testing, 46% of ChatGPT agent visits begin in reading mode: plain HTML with no images, CSS, JavaScript or schema. If your content relies on any of those to be complete, agents visiting pages that look fine in Google Search Console may be finding them partially empty. Rankings and AI visibility can diverge significantly.
Yes. Local service queries are exactly the high-intent territory where AI citation matters most. When someone asks an AI platform for a plumber in their suburb or an NDIS provider in their area, locally specific content and correctly configured crawler permissions both influence the answer. For trades SEO and NDIS providers, server-rendered HTML, correctly configured robots.txt and genuinely local content are the minimum viable setup for AI visibility.
AI visibility comes down to two things your site either gets right or does not: can agents read it, and does the content give them something worth citing. An AI visibility audit maps both and tells you which one to fix first.



