

Most conversations about Generative Engine Optimisation (GEO) stay at the surface. Publish good content. Build topical authority. Answer questions clearly. All of that is true — and all of it is table stakes.
What almost nobody is talking about is the infrastructure layer. The technical architecture that determines whether an AI agent can find your business, understand what you do, trust your data, and take action on your behalf.
In 2026, GEO is no longer just a content strategy. It is a technical discipline. And the gap between businesses who understand this and those who don’t is already opening.
This piece breaks down the three technical pillars of GEO that matter right now: llms.txt, Model Context Protocol (MCP), and advanced schema markup. Not as theory. As practical infrastructure decisions with real commercial implications for Melbourne businesses competing in an AI-mediated discovery environment.
The Search Stack Has Changed. Most Websites Haven’t.
For two decades, SEO operated on a single primary assumption: a human will type a query, Google will return a ranked list of pages, and the human will click. Optimise for that sequence and you capture traffic.
That sequence is breaking down. It is not gone. Google still processes billions of traditional queries every day. But an increasing share of discovery now happens through a fundamentally different mechanism.
AI agents, whether that’s ChatGPT answering a user’s question, Perplexity assembling a research summary, Claude working through an agentic task, or Google’s AI Mode synthesising a response do not browse websites the way humans do. They do not click through menus. They do not scan navigation bars. They request structured data, parse machine-readable signals, and make decisions about which sources are worth referencing before a human ever sees the output.
The question for businesses in 2026 is not ‘how do I rank higher?’ It is ‘how do I make my business legible to the systems that are generating answers before my customer even types a search query?’
That question has a technical answer. And it starts with understanding how AI SEO has evolved from a content discipline into a machine-readability discipline.
llms.txt: Your Site’s Introduction to the Agentic Web
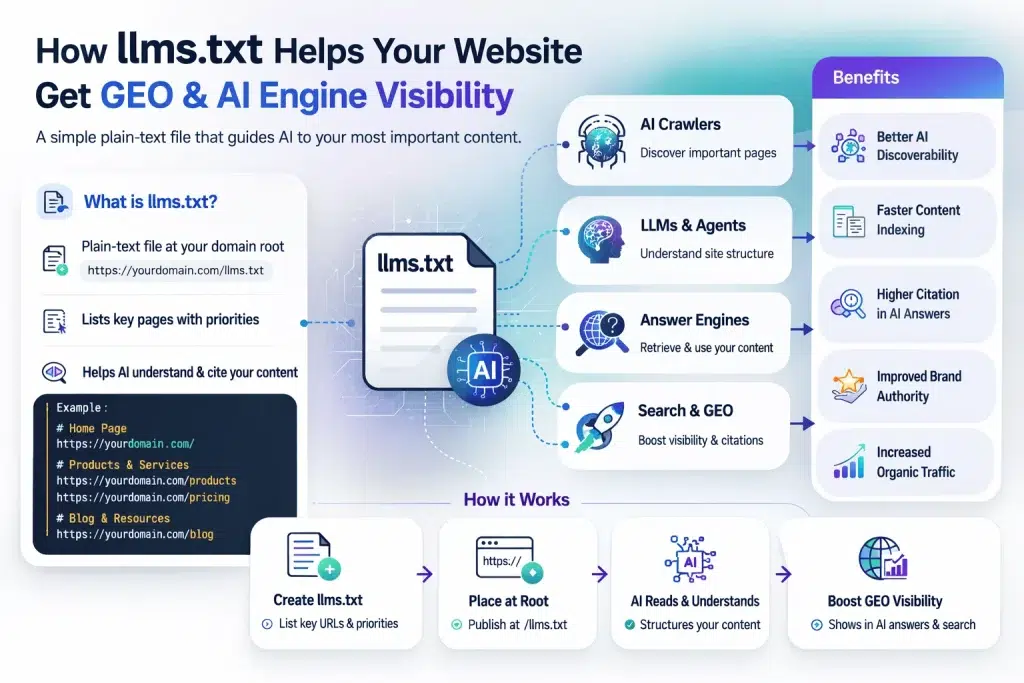
In September 2024, Jeremy Howard founder of Answer.AI proposed a deceptively simple idea: what if websites published a plain-text file, sitting at the root of their domain, that gave AI systems a curated, prioritised map of their most important content?
That file is llms.txt. And while the SEO community has been debating whether it matters, over 844,000 websites have already implemented it including Anthropic (for Claude’s documentation), Cloudflare, and Stripe.
Why llms.txt Exists: The Token Problem
Here is the technical reality that makes llms.txt necessary. Modern websites are architecturally hostile to AI agents. Navigation bars, cookie banners, JavaScript-heavy layouts, sidebar widgets, and footer markup all consume tokens when an AI system tries to parse your site in real time. A page that takes 16,000 tokens to process in raw HTML can drop to around 3,150 tokens in clean Markdown an 80% reduction, according to Cloudflare’s own analysis.
This matters because AI agents operating under inference constraints generating live answers while a user waits make prioritisation decisions based on what is fast and parseable. If your key service pages are buried under structural noise, they get deprioritised or skipped.
llms.txt solves this by acting as a curated shortcut. Rather than making an AI agent excavate your site architecture to find what matters, you surface it directly.
What llms.txt Actually Contains
The file format is intentionally lean, written in Markdown because that is effectively the native language of large language models. A well-structured llms.txt includes:
- An H1 with your site or brand name – this becomes the AI’s anchor reference for your entity
- A blockquote summary of 1–3 sentences — often what the AI uses as its ‘mental model’ of what you do
- Prioritised links to your most important pages with descriptive labels — service pages, case studies, methodology content, and authority-building resources
- Optional sections for content you want to exclude or contextual instructions about how your content should be interpreted
Here is a simplified example of what this looks like in practice:
# Predicta Digital
> Melbourne-based SEO and AI search agency helping service businesses get found across traditional and AI-powered search environments.
## Core Services
– [AI SEO](https://predictadigital.com.au/services/ai-seo/): Structured optimisation for ChatGPT, Perplexity, and Google AI Mode
– [SEO Services Melbourne](https://predictadigital.com.au/services/seo/): Technical and content SEO for Melbourne businesses
– [SEO for Tradies](https://predictadigital.com.au/services/seo-for-tradies/): Local search and AI visibility for trade businesses
– [SEO for Plumbers](https://predictadigital.com.au/services/seo-for-plumbers/): Suburb-level visibility for Melbourne plumbing businesses
## About
– [Predicta Digital](https://predictadigital.com.au/): Agency overview, approach, and client outcomes
The Honest Assessment: What llms.txt Does and Does Not Do
Here is where I will be direct with you, because there is a lot of breathless content out there overclaiming on this.
Google’s Gary Illyes has stated explicitly that llms.txt is not used for ranking in AI Overviews. A study of 300,000 domains found no statistical correlation between having an llms.txt file and being cited by LLMs. No major AI lab has officially committed to honouring the file as a standard.
And yet: OpenAI’s crawler has been observed fetching llms.txt files the day after implementation. Anthropic listed llms.txt in Claude’s official documentation. Google probed for it across their own developer properties. The file is trivially cheap to implement and is effectively a bet on a standard that has genuine institutional momentum behind it.
My position: llms.txt is not a silver bullet and anyone selling it as one is misleading you. It is a low-cost, high-optionality infrastructure bet. You implement it, you keep it updated, and you treat it as part of a broader technical GEO stack — not a standalone tactic.
The more important change happening alongside llms.txt is at the server and protocol layer. Which brings us to MCP.
Model Context Protocol: The Infrastructure Shift Nobody in SEO Is Talking About Enough
If llms.txt is a curated map for AI agents, MCP is the protocol that lets them actually operate inside your digital environment.
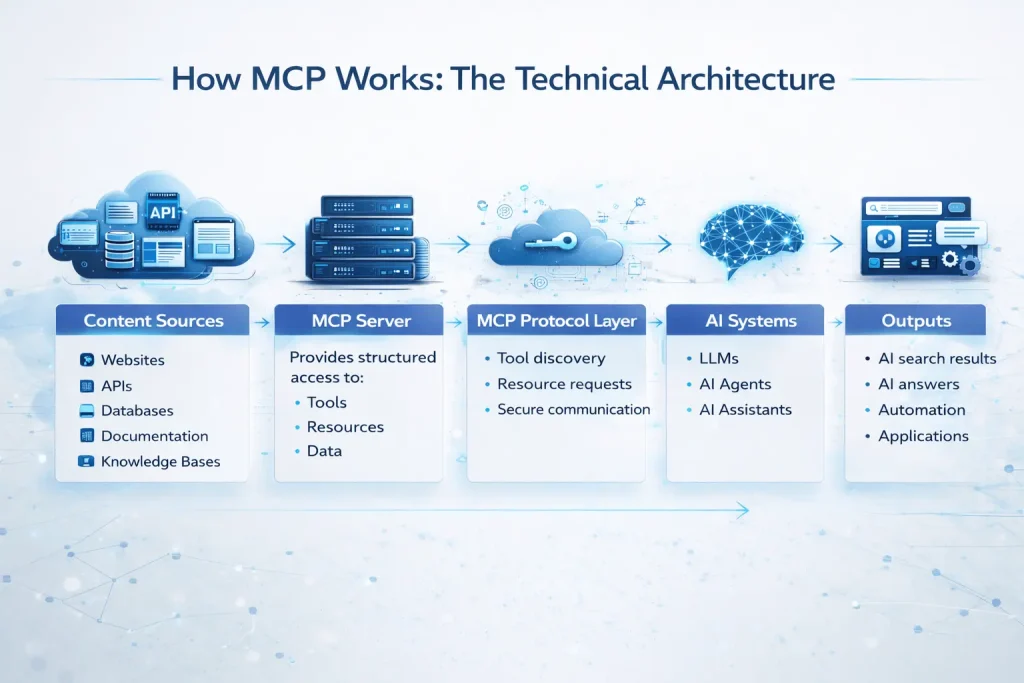
Model Context Protocol was introduced by Anthropic in November 2024 as an open standard for connecting AI systems to external data sources and tools. The clearest analogy I have seen is USB-C: before a universal standard, every device needed its own proprietary connection. MCP does for AI agents what USB-C did for device connectivity — it standardises the interface so any AI system can connect to any data source or tool through a consistent, predictable protocol.
How MCP Works: The Technical Architecture
MCP operates on a client-server model:
- The MCP host is the AI application — Claude, ChatGPT, Perplexity, or an enterprise AI agent
- The MCP server is what you expose — your data, your tools, your content endpoints
- The protocol layer standardises how these two communicate, eliminating the need for custom integrations
In practical terms, this means an AI agent can query your inventory in real time, pull current pricing without scraping your website, access your service catalogue with proper context, or execute a booking workflow all through a standardised interface rather than by trying to read your HTML like a clumsy human.
For SEO professionals, this represents a category shift. Traditional technical SEO optimises how pages are crawled and indexed. MCP optimises how AI agents interact with your digital infrastructure as an operating environment.
Google’s WebMCP: The Agentic Web Gets Official
In February 2026, Google announced an early preview of WebMCP — a browser-native adaptation of the Model Context Protocol standard. This is significant because it moves MCP from a developer ecosystem play to a web standard.
WebMCP allows websites to publish what Google calls a ‘Tool Contract’ — a structured, discoverable list of actions that AI agents can call directly through the browser API navigator.modelContext. Instead of an agent trying to guess which button does what, it can call a defined function: bookAppointment(), requestQuote(), or searchInventory().
Google has proposed two implementation approaches:
- Declarative API: Standard actions expressed in HTML forms — signups, enquiries, support requests. For many service businesses, this is where implementation starts.
- Imperative API: Complex dynamic interactions requiring JavaScript execution — multi-step booking flows, configuration tools, filtered product searches.
Dan Petrovic called WebMCP the biggest shift in technical SEO since structured data. Glenn Gabe called it a big deal. I agree with both assessments — with the caveat that adoption will be gradual and the businesses who will benefit most are those who start treating their websites as agent-operable interfaces now, before the standard is fully formalised.
MCP and the Agentic SEO Imperative
Here is the commercial reality underneath the technical specification. When AI agents become the primary interface through which users execute intent — booking a plumber, requesting an SEO audit, comparing service providers — websites that cannot be operated by those agents become effectively invisible.
This is not a hypothetical future. Vercel reports that 10% of new signups now come directly from AI referrals. Companies with MCP-compatible infrastructure are already seeing AI agents complete multi-step journeys on their behalf. For Melbourne service businesses, the question is not whether this shift will affect you — it is how prepared your infrastructure is when it does.
The businesses currently investing in SEO services Melbourne-wide that account for agent-readiness — clean forms, stable UX flows, structured data, and clear action pathways — are building a compound advantage.
Advanced Schema Markup: The Structured Data Layer That Determines AI Citability
Schema markup is not new. Most SEO practitioners have been implementing it for years. But the way AI systems use schema in 2026 is fundamentally different from how Google used it to generate rich snippets in 2019.
In traditional SEO, schema helped you earn visual enhancements in search results — star ratings, FAQ dropdowns, event cards. In GEO, schema is doing something more foundational: it is telling AI systems what your content means, who created it, what entity it belongs to, and how confident the system should be in citing it.
Content with proper schema markup has a 2.5x higher probability of appearing in AI-generated answers. Sites implementing structured data and FAQ blocks saw a 44% increase in AI search citations in BrightEdge research. These are not marginal gains.
The Eight Schema Types That Matter Most for GEO
1. Organisation Schema
This is your entity anchor. Organisation schema establishes your brand as a distinct, verifiable entity in AI knowledge graphs. The critical properties are @id (a stable, canonical URL identifier for your business), sameAs (links to your Google Business Profile, LinkedIn, Wikidata if applicable, and other authoritative mentions), name, url, description, and contactPoint.
Without a well-formed Organisation schema, AI systems have to infer your business identity from page content. With it, they can resolve your entity directly and attribute citations accurately.
2. LocalBusiness Schema
For Melbourne service businesses, LocalBusiness schema is non-negotiable. It signals geographic relevance to AI systems handling location-intent queries — ‘who is the best SEO agency in Melbourne?’ or ‘plumber near Richmond’. The key properties are address, geo (latitude/longitude), areaServed, openingHoursSpecification, and telephone.
A critical rule: your LocalBusiness schema must match your Google Business Profile data exactly. Inconsistencies between schema markup and GBP confuse AI entity resolution and reduce citation confidence.
3.Service Schema
Most service businesses use Product schema by default. For businesses that sell services rather than physical products, Service schema and OfferCatalog provide more precise signals. Use serviceType, provider, areaServed, and hasOfferCatalog. For professional services, subtypes like LegalService, FinancialService, or in the SEO context, a ProfessionalService type with detailed serviceOutput properties, give AI systems the specificity they need to match your offering to user intent.
4.FAQPage Schema
FAQPage schema experienced a split identity after Google reduced its rich result eligibility for most domains in 2023. It became less visible in traditional SERPs — and simultaneously more valuable for AI citation.
The reason is structural. Research shows that 78% of AI-generated answers include list formats, and FAQ schema naturally structures content as question-answer pairs — the exact format AI systems prefer when generating responses. ChatGPT favours FAQPage and Article schema for its conversational answer format. Perplexity relies on schema-defined entities to populate its multi-source responses.
Keep FAQ answers between 40–60 words for optimal AI extraction. Front-load the direct answer. Avoid promotional language — AI systems penalise content that reads like marketing copy rather than authoritative information.
5. Article and BlogPosting Schema
For content-heavy pages, Article schema provides critical provenance signals: who wrote it, when it was published, when it was last updated, and which organisation it belongs to. AI systems use dateModified aggressively — stale dateModified values cause AI engines to deprioritise content even when it has been substantively refreshed. Update your dateModified every time you revise content, not just when you publish new pieces.
6.Person Schema
This is an underused E-E-A-T signal. If your content is authored by named individuals with demonstrable expertise, Person schema with sameAs links to LinkedIn profiles, published research, or other authoritative sources strengthens AI systems’ confidence in citing that content. For agency contexts, this means attributing thought leadership content to real practitioners, not generic ‘editorial team’ attributions.
7.BreadcrumbListSchema
Often overlooked, BreadcrumbList schema helps AI systems understand site hierarchy. In the context of agentic crawling, where an agent may be navigating your site to find specific information, a clear hierarchical structure reduces navigation uncertainty and improves the accuracy of content retrieval.
8. How To Schema
For instructional content, HowTo schema structures step-by-step information in a format AI systems can extract and present directly. In a GEO context, this is particularly powerful for trade and service businesses — a plumber publishing a structured HowTo on diagnosing a blocked drain, or an SEO agency publishing a structured HowTo on conducting an AI search audit, is giving AI systems directly citable, high-confidence content.
Schema Implementation: The Technical Non-Negotiables
Format: Use JSON-LD exclusively. Every AI engine tested in 2026 prefers it because it is cleanly separated from HTML and easier to parse programmatically. Google’s guidance explicitly recommends JSON-LD for AI-optimised content.
The @id and sameAs pattern: These two properties are the mechanism through which AI systems resolve your entity across the web. Every major entity in your schema — your Organisation, your key People, your Service locations — should have stable @id values and sameAs links to authoritative external references.
Consistency: Schema data must match visible page content. AI systems cross-reference structured claims against page content. Mismatches reduce citation confidence and can trigger explicit deprioritisation. A dateModified that does not reflect actual content changes, or a description in schema that contradicts the page copy, undermines the trust signal you are trying to establish.
Nesting: Rather than implementing separate, disconnected schema blocks, nest related schemas to show relationships. An Article nested within an Organisation with an author Person creates a richer entity graph than three isolated schema implementations.
Validation cadence: Run schema through Google’s Rich Results Test and Schema Markup Validator on every major content update. Establish a quarterly schema audit as a standard practice. Stale or broken schema is silently ignored — you will not always know it has stopped working unless you check.

Machine-Consumable Pages: Designing for AI Agents, Not Just Human Readers
Beyond the specific protocols and markup types, there is a broader design principle emerging in GEO that is worth naming directly: machine-consumable page architecture.
Traditional UX design optimises for human cognitive patterns — visual hierarchy, emotional response, progressive disclosure. Machine-consumable page design adds a parallel layer: structuring pages so AI agents can parse them accurately and efficiently without human guidance.
robots.txt: The Agentic Crawl Permission Layer
Most businesses have a robots.txt that manages traditional search crawler access. In 2026, that file also needs to account for a distinct taxonomy of AI crawlers, each with different functions:
- Training crawlers (GPTBot, ClaudeBot, Google-Extended): Scrape content to train or fine-tune models
- Search/retrieval crawlers (OAI-SearchBot, PerplexityBot, Claude-SearchBot): Index content for real-time citation in AI answers
- User-triggered fetchers (ChatGPT-User, Claude-User, Perplexity-User): Activate when a real user’s query prompts live content retrieval
The distinction matters because different businesses will have different positions on each category. A business that wants AI citation visibility needs to explicitly allow search/retrieval crawlers. A business with proprietary data may want to block training crawlers while allowing retrieval access. Without deliberate robots.txt configuration, you are leaving this entirely to default crawler behaviour.
The Content Architecture That AI Systems Reward
Across all three technical layers — llms.txt, MCP, and schema — there is a consistent signal about what makes content AI-citable. It is not complexity. It is clarity with verifiable structure.
- Direct answers within the first 60–80 words of a section
- Clear heading hierarchy that mirrors logical question-answer relationships
- Structured lists and comparison tables over dense prose paragraphs
- Explicit author attribution with verifiable credentials
- Consistent factual claims that can be cross-referenced against schema data
- Freshness signals — updated dateModified, recent publication dates, current statistics
This is not a compromise between human readability and machine readability. Well-structured content is better for human readers too. The businesses winning in GEO are not writing for robots — they are writing with the precision and structure that authoritative sources have always required.
The Practical GEO Technical Stack for Melbourne Businesses in 2026
Let me bring this down to a practical implementation framework. The following is the technical GEO stack I would recommend for a Melbourne service business operating in a competitive vertical — whether that is professional services, trades, health, or digital services.
Layer 1: Entity Foundation
- Organisation schema with @id, sameAs, and complete contact properties
- LocalBusiness schema aligned exactly with Google Business Profile
- Person schema for key practitioners and authors
- All schema in JSON-LD format, validated quarterly
Layer 2: Content Citability
- FAQPage schema on all FAQ sections with 40–60 word answers
- Article/BlogPosting schema on all content pages with current dateModified
- HowTo schema on instructional content
- Service schema on all service pages with areaServed and hasOfferCatalog
Layer 3: Machine-Readable Infrastructure
- llms.txt at root domain with curated priority content and accurate descriptions
- robots.txt updated to deliberately configure AI crawler access by category
- Cloudflare Markdown for Agents or equivalent server-side Markdown serving for AI requests
- Clean form architecture for WebMCP declarative API readiness
Layer 4: Agentic Readiness
- Structured action pathways for key conversion flows (quote request, contact, booking)
- Stable URL architecture with no redirect traps or broken navigation flows
- Fast load times — AI agents under inference constraints favour fast-responding sources
- WebMCP tool contract review as the standard matures through 2026
None of this replaces foundational SEO. Google’s own documentation confirms that AI Overviews draw from traditional SEO signals — authority, relevance, freshness, E-E-A-T. The technical GEO stack layers on top of SEO foundations. It does not substitute for them.
Why This Matters Now, Not Later
There is a pattern in every major search infrastructure shift. Early adopters build compound advantages while the market is still debating whether the shift is real. By the time the majority catches up, the gap is structural — not tactical.
Mobile-first indexing followed this pattern. Page experience followed it. Schema rich results followed it. Each time, the businesses that implemented early spent less effort to maintain visibility than those who scrambled to retrofit compliance after the shift was complete.
GEO is following the same pattern, but faster. AI search adoption is accelerating at 527% year-on-year. AI Overviews now appear in more than 50% of Google searches. ChatGPT is the fourth most-visited website globally. The window for early adoption advantage is open — but it will not stay open indefinitely.
For Melbourne businesses competing in services, trades, professional services, and local markets, the AI SEO infrastructure decisions you make in the next six months will shape your visibility for the next several years. The technical foundations are not complex — but they require deliberate implementation, and they compound over time.
What to Do Next
If you are reading this and wondering where to start, here is the honest answer: start with the entity layer. Get your Organisation and LocalBusiness schema right, consistent, and validated. Make sure your Google Business Profile matches your schema data exactly. That single step alone meaningfully improves AI entity resolution for your business.
Then implement llms.txt. It takes less than an hour. Populate it with your priority service pages and a clear brand description. Update it whenever your key content changes.
Then audit your robots.txt for AI crawler configuration. Decide deliberately which categories of AI access you want to allow.
From there, the content citability layer — FAQPage, Article, Service, HowTo schemas — builds progressively. Each addition incrementally improves the structured signals AI systems use to evaluate and cite your content.
The agentic readiness layer — WebMCP tool contracts, Markdown serving, MCP-compatible infrastructure — is where the frontier is moving. It requires more development resource and the standards are still maturing. But the foundation work you do now — clean forms, stable UX flows, structured action pathways — is directly preparatory for that layer.
If you want to understand where your current technical GEO position stands, our SEO services Melbourne team runs structured GEO audits that map your entity foundation, schema coverage, machine-readability gaps, and agentic readiness across all four layers. The audit gives you a prioritised implementation roadmap — not a list of every possible thing you could do, but a sequenced plan based on where the highest-impact gaps are for your specific business and competitive context.
FAQs: llms.txt, MCP, and Schema for GEO
Does llms.txt directly improve my Google rankings?
No. Google has confirmed it does not use llms.txt for ranking in AI Overviews or traditional search. The file is designed for LLM agents and agentic crawlers, not for Googlebot. Its value is in AI citation visibility and agent discoverability, not direct ranking impact.
Is MCP relevant to my business if I’m not a technology company?
Yes — increasingly so. MCP and WebMCP are relevant to any business that has conversion actions AI agents might execute on behalf of users: booking appointments, requesting quotes, searching service catalogues, or submitting contact forms. Service businesses, trades operators, and professional services firms all have action pathways that benefit from agent-readable infrastructure.
Which schema types should I implement first?
For Melbourne service businesses: Organisation and LocalBusiness first (entity foundation), then FAQPage on your key service pages and blog content, then Service schema on your service pages. Article schema on content pages and Person schema on author profiles follow from there. Validate everything in JSON-LD format using Google’s Rich Results Test.
How does this relate to traditional SEO?
Traditional SEO remains foundational. Google’s own guidance confirms that AI Overviews draw from the same authority and relevance signals as traditional search. The technical GEO stack described in this article layers on top of strong SEO services Melbourne-wide foundations — it does not replace them. Think of it as expanding your optimisation surface from one environment (Google’s blue links) to multiple environments (AI Overviews, ChatGPT, Perplexity, agentic workflows).
How often should I update my llms.txt and schema markup?
llms.txt should be updated whenever you add major new service pages, publish significant content, or change your business description. Schema markup should be validated quarterly as a minimum, and date Modified should be updated every time substantive content changes. Out-of-date schema is silently ignored by AI systems — regular maintenance is non-negotiable.
Is this relevant for trade businesses like plumbers and electricians?
Absolutely. Local service queries are high-intent AI search territory. When a Melbourne homeowner asks ChatGPT for a plumber recommendation in their suburb, LocalBusiness schema, Service schema, and clear llms.txt entries directly influence whether your business appears in that response. Our SEO for plumbers and SEO for tradies services now incorporate GEO technical foundations as standard, because the businesses with this infrastructure in place are already capturing discovery moments that competitors are invisible to.